Amazon Web Services is one of the top cloud providers and is used by Netflix, Reddit, Facebook, and many other household names. Many retail businesses also favor this cloud computing platform, including Amazon, Under Armor and Amway.
Amazon Web Services are easy-to-use, scalable, have no capacity limits, and guarantee speed and agility.
One of our e-commerce clients also reaps the benefits of Amazon Web Services.
In this case, the platform helps to process millions of clickstream events generated by mobile and desktop users on a daily basis, record near-real-time customer activity metrics and visualize them on the dashboard almost instantaneously.
To get a visual representation of metrics, our team uses DataDog. It’s a flexible solution for fast integration with a lot of systems, applications, and services.
DataDog offers full API access, customizable monitoring dashboards, 80+ turn-key integrations, data integration, and easy computations.
To get the most out of AWS and DataDog, many e-commerce companies also create real-time customer activities dashboard from clickstream. These dashboards help marketing teams see almost real-time user activity metrics, get statistics for periods, compare periods and make on-the-spot decisions during campaigns and special offers.
Moreover, careful examination of the dashboard by Company Operation Center (COP) can easily spot issues with internal services almost as they appear. For example, if the payment service fails, an abnormal drop in buyers can be seen on the dashboard. This would be the cause for COP to start its investigation immediately. As a result, response time decreases and accidents are resolved quicker. This also protects the company’s reputation and reduces unforeseen expenses.
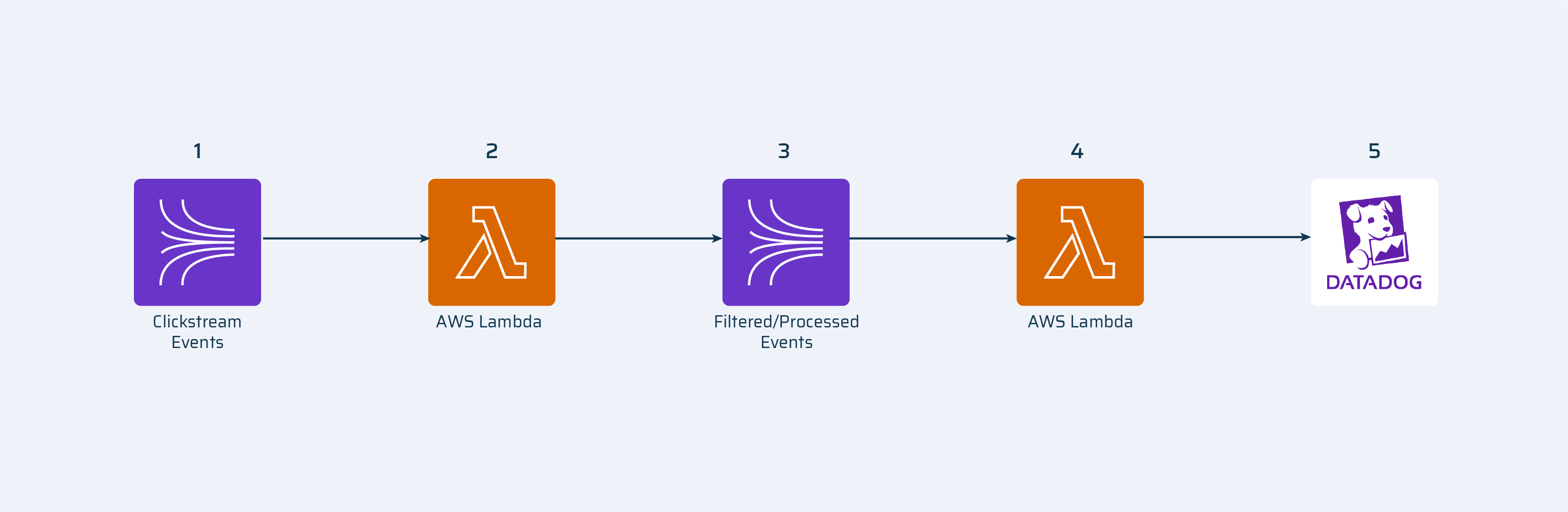
Standard Stream Architecture
Kinesis Stream – all clickstream events are produced into this stream
Amazon lambda(processing) – this lambda consumes clickstream events from the stream. It cleans data, filters needed events and produces them to a new stream.
Kinesis Stream – filtered and cleaned clickstream events are produced here.
Amazon lambda(sending) – this lambda consumes filtered events from Kinesis stream and sends them to DataDog.
DataDog – monitoring and analytics service.
This architecture works well on a day-to-day basis. Butwhen the clickstream gets a 10x increase in online users (for example, on Black Friday or during sales periods), the number of incoming events rises to such an extent that lambda cannot process them at the same pace. As a result, the queue of events rises, as well as the lambda iteration age.
Our task was to provide a solution for such peak times.
First, we analyzed what wouldn’t work:
Increasing memory for lambda. Processing of 200 events by lambda with 128Mb takes from ~70-120ms and sending events (external call) to DataDog takes ~100-200ms, the sum is around ~220-320ms.
or will cost a lot more money:
Increasing the number of shards. 256Mb lambda will process events for ~35-70ms, sending events to DataDog will still be ~100-200ms.
We knew we had to rebuild the data pipeline to solve this bottleneck issue.
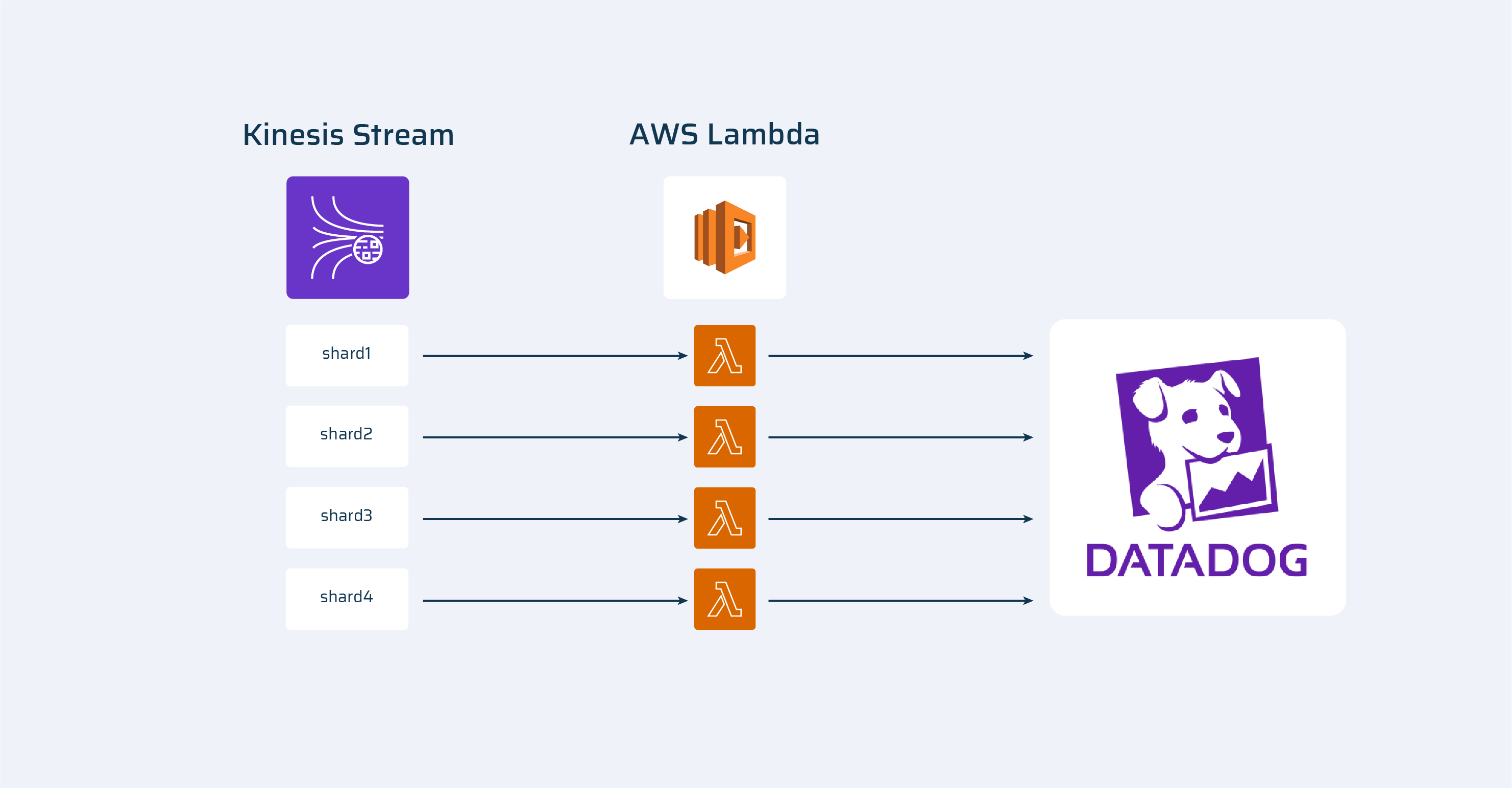
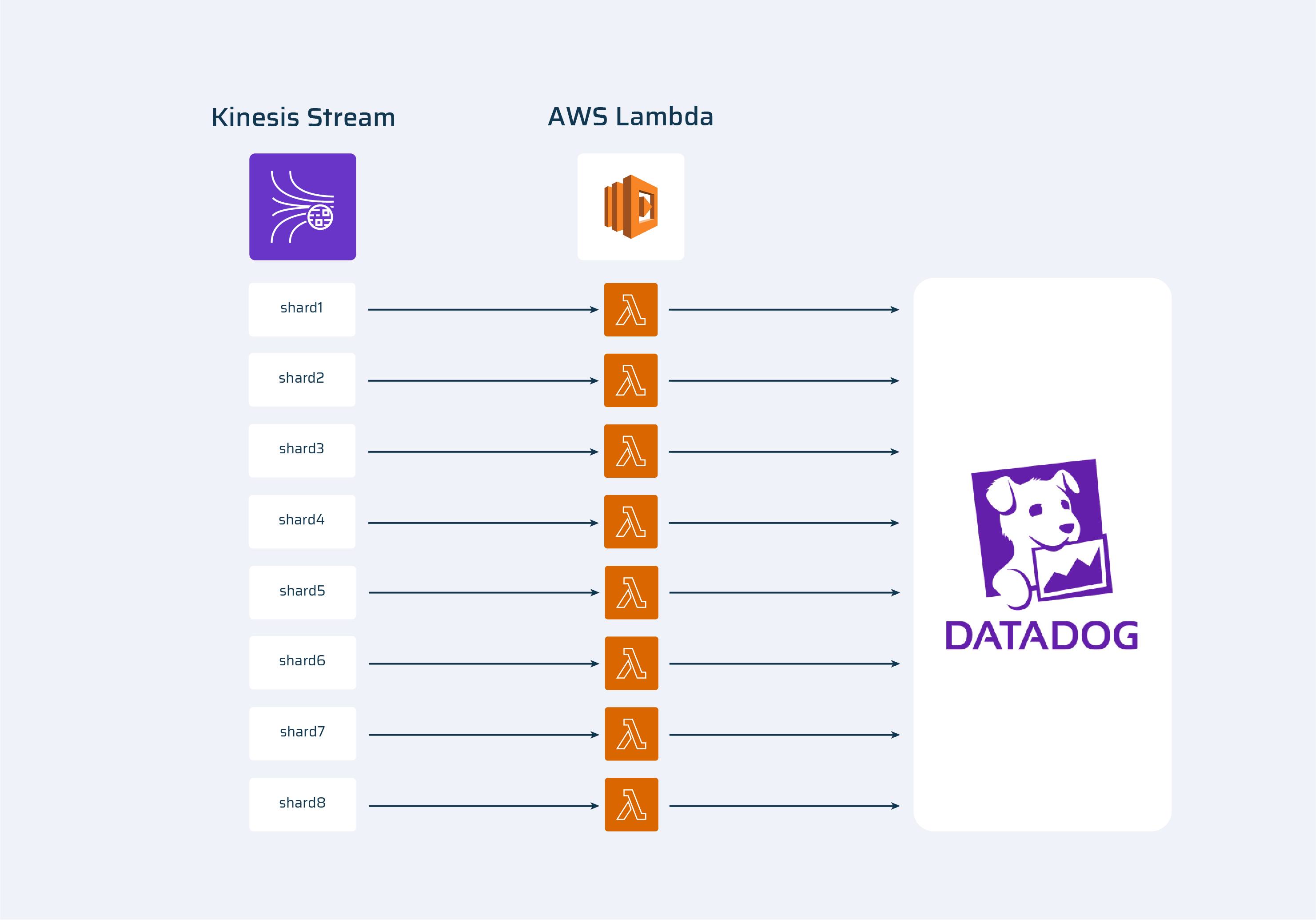
One of the options was to increase the number of lambdas that were sending events into DataDog. It could only be done by increasing the number of Kinesis shards because only one instance of lambda is running at each shard at the same time.
From:To:
This is a working solution, but it’s a resource- and money overrun. Thus, we moved on to Plan B.
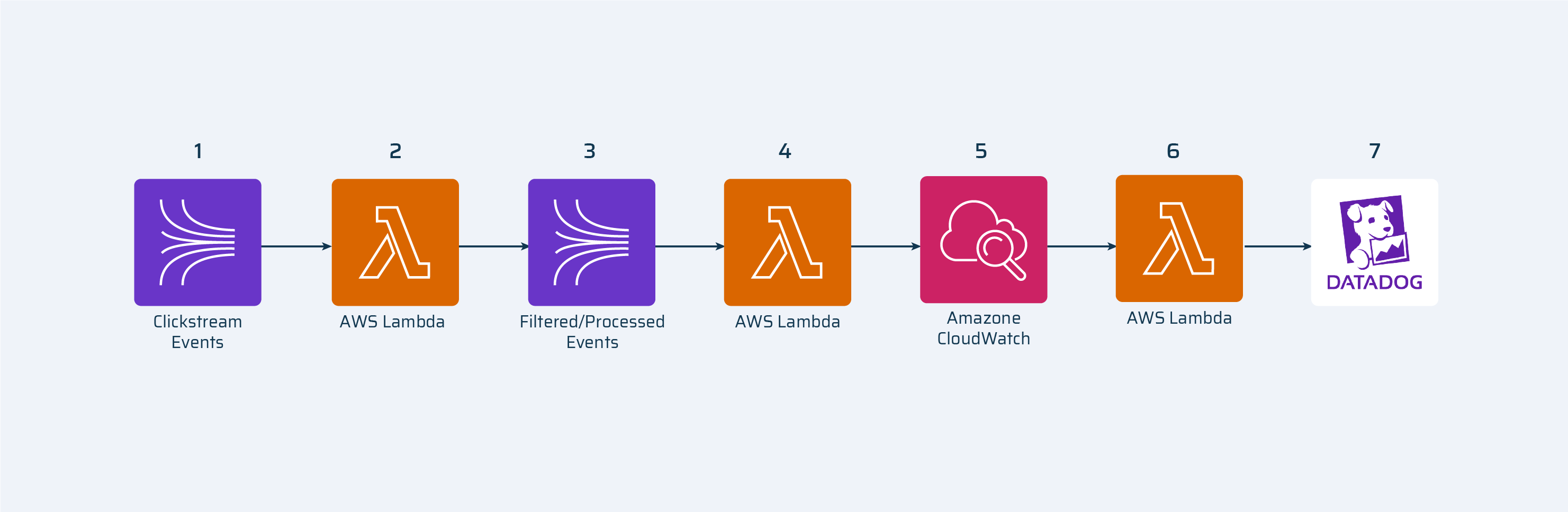
Our Solution to Remove Bottlenecks in Calls to External Services
The central idea in our solution was to separate external calls and the creation of events.
1. Kinesis Stream – all clickstream events are produced into this stream.2. Amazon lambda(processing) – this lambda consumes clickstream events from the stream, cleans data, filters needed events and produces them to a new stream.3. Kinesis Stream – filtered and cleaned clickstream events are produced here.4. Amazon lambda – this lambda consumes filtered events from Kinesis stream and sends them to CloudWatch log group.5. Amazon CloudWatch log group – Amazon service where we can log out logs from lambda.6. Amazon lambda – this lambda consumes Datadog metrics from CloudWatch and sends them to Datadog.7. DataDog – monitoring and analytics service.
Long story short, we have created a separate lambda to send metrics to DataDog. A lambda that was previously creating metrics and sending them further now only creates events and logs them out to CloudWatch. Logging to Cloudwatch AWS is realized in async (background) mode and does not require additional time.
The new lambda reads Cloudwatch logs, gets events and sends them to DataDog. It doesn’t consume events from Kinesis stream so we can run as many lambda instances as we need, limited only by AWS account limitation (1000 instances).
This smart approach enables us to handle event spikes without scaling, so we can optimize costs.
Author: Viktor Presniakov, Data Engineer, Zoolatech